
Enterprise data observability is the practice of monitoring, managing, and maintaining data to ensure its quality, availability, and reliability across an organization’s processes, systems, and pipelines. It involves understanding the health of data throughout its lifecycle and goes beyond traditional monitoring by identifying, troubleshooting, and resolving data issues in near-real time.
Implementing data observability tools is crucial for addressing bad data issues, which can impact data reliability. These tools automate monitoring, triage alerting, tracking, comparisons, root cause analysis, logging, data lineage, and service level agreement (SLA) tracking. They collectively contribute to a comprehensive view of end-to-end data quality and reliability.
For modern data teams, where data is used for insights, machine learning models, and innovation, a data observability solution ensures that data remains a valuable asset. It needs to be consistently integrated throughout the entire data lifecycle, standardizing and centralizing data management activities across teams.
Data observability is considered the natural evolution of the data quality movement, enabling the practice of data operations (DataOps). It plays a crucial role in preventing and addressing data issues that can have significant consequences for organizations.
The introduction of “DataStage as a Service Anywhere” is announced, allowing the execution of ETL and ELT pipelines in any cloud, data center, or on-premises environment.
The importance of data observability is highlighted by the fact that many organizations face data quality concerns and a lack of trust in their data. Bad data can have substantial financial consequences, as seen in the example of Unity Software’s stock plunge and lost revenue.
Data observability is positioned as the best defense against bad data, ensuring the complete, accurate, and timely delivery of data. It helps prevent data downtime, meet SLAs, and maintain trust in the data.
The evolution of data systems with increased functionality brings challenges such as more external data sources, complicated transformations, and a focus on analytics engineering. Data observability aligns with the DataOps movement, facilitating an agile delivery pipeline and feedback loop for efficient product creation and maintenance.
The DataOps cycle consists of detection, awareness, and iteration stages. Detection involves validation-focused checks, awareness focuses on visibility and metadata, and iteration emphasizes process-focused activities for repeatable and sustainable standards.
Well-executed data observability delivers benefits such as higher data quality, faster troubleshooting, improved collaboration, increased efficiency, improved compliance, enhanced customer experience, and increased revenue.
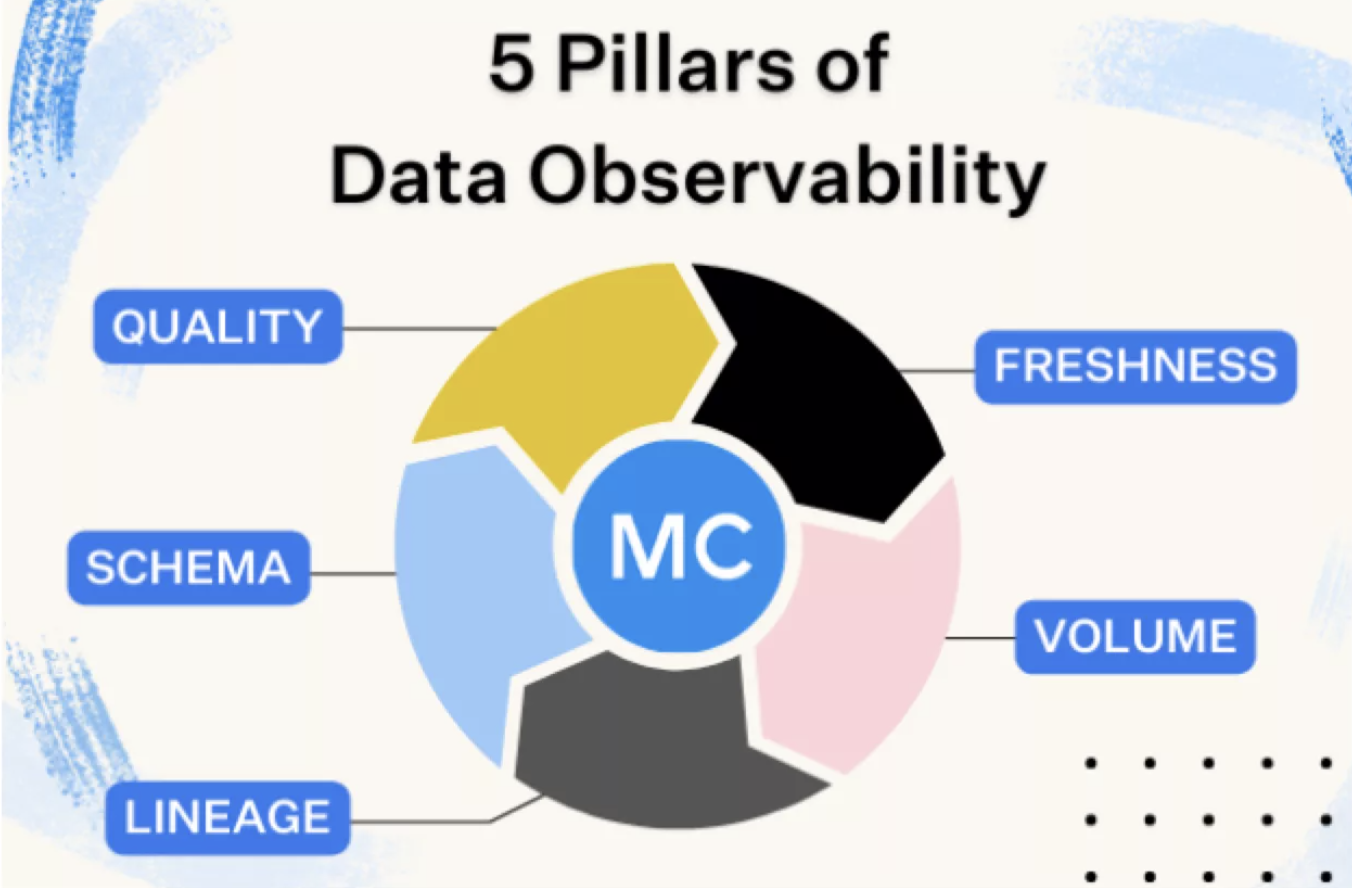
The five pillars of data observability—freshness, distribution, volume, schema, and lineage—provide insight into the quality and reliability of data. They cover aspects like data currency, field-level health, data amount, data organization, and data flow.
Data observability differs from data quality, with observability supporting quality but not guaranteeing it. Data quality monitoring examines various dimensions like accuracy, completeness, consistency, validity, reliability, and timeliness.
Data observability and data governance are complementary processes. While data governance ensures data availability, usability, consistency, and security, data observability monitors changes in data quality, availability, and lineage.
The hierarchy of data observability involves monitoring operational health, data at rest, and data in motion. It emphasizes the interconnectedness of dataset and pipeline monitoring and introduces column-level profiling and row-level validation for finer grains of observability.
Implementing a data observability framework involves defining key metrics, choosing appropriate tools, standardizing libraries, instrumenting the data pipeline, setting up a data storage solution, implementing data analysis tools, configuring alerts, integrating with incident management platforms, and regularly reviewing and updating the observability pipeline. The process is continuous, requiring learning and refinement. Starting small and incrementally expanding observability capabilities is crucial.